Void Security
Just another security blog.
Splunk insfrastructure and AWS Spot instances
2020-09-28
Before we go any further, let me get some disclosures out of the way first. None of this was tested in production, nor am I an Splunk expert or have ever managed a Splunk infrastructure in production. My experience with Splunk is limited to a few universal forwarders, deployment servers and Splunk Cloud.
While talking with a friend about AWS Spot Instaces a few weeks ago an idea came to my mind “how about using spot instances for a Splunk distributed deployment?”, the savings on hardware could be significant. So, having only personally managed a few universal forwarders and deployment servers, my plan was to have indexers and search heads in different instances, deploying everything with CloudFormation. Here is what I managed to do, the code I wrote will be referenced at the end of the post if you would like to take a look, just keep in mind that this is version 1.0, so there are some hardcoded credentials and what not, some Splunk services that I still want to automate (like a deployment server and universal forwarders), and possible some missing AWS configs too.
AWS Spot Instances and CloudFormation
Spot instances have a lot of cool use cases, like if you need a quick burst of cheap computer power, or just need a lot of instances really. When you request a spot instance, you can set a maximum price that you want to pay, if it goes over that, you can chose to terminate or stop the instance, or even keep using it, but from what I saw, prices don’t fluctuate that much, so I think it should be safe to have the instances terminate and AWS would deploy another one, and since everything is automated, it would join your Splunk infrastructure, copy the data over and everything should be fine. All other configs are pretty straight forward, you select how many instances you want to deploy, their configuration and everything else that you can do with a normal on-demand instance.
First let me show the instance templates. We create a default SecurityGroup, that is used on all instances, it’s used to open the necessary ports for the instances to talk to each other and so you can access the Splunk Search Head after it’s deployed. On the script I’m providing, there are some hardcoded IPs that you should probably change if you are going to use it, maybe I’ll look into a better way of doing this in a v2. There is also a role that is attached to the instances, because they need to get the IP of the master instance on deployment, so they need access to describe EC2 instances. There isn’t much to talk about them, so I’ll instead talk about the instance template per se. The following are some snippets from the SplunkPeer instance on the InstanceLaunchTemplate.yaml file.
SplunkPeer:
Type: AWS::EC2::LaunchTemplate
Properties:
LaunchTemplateName: SplunkPeer
LaunchTemplateData:
ImageId: ami-0c94855ba95c71c99
IamInstanceProfile:
Arn: !GetAtt SplunkEC2PermissionProfile.Arn
InstanceType: t3a.large
KeyName: splunk #This key must exist
SecurityGroupIds:
- !GetAtt SplunkSecurityGroup.GroupId
This first part is really just selecting what instance you want and doing some basic configuration. Make sure you select a KeyName that exists on your AWS account, otherwise you won’t be able to access it later via SSH (it probably will fail the deployment first, I’m not sure), for the next version I definitely want to use AWS Session Manager (more information here), but for now this was good enough for me.
BlockDeviceMappings:
- DeviceName: /dev/xvda
Ebs:
VolumeSize:
25
TagSpecifications:
-
ResourceType: instance
Tags:
-
Key: Name
Value: SplunkPeer
Here I’m setting my storage, which you probably will want to increase if you are gonna ingest any data, and adding some tags, which are used for finding the Splunk Master Instance on the next part. One thing I thought of doing was adding two storages, one for the base system and another, larger, for the Splunk data, so if a instance was killed, you could just reattach the disk, but this would need more configuration on both Splunk and CloudFormation, so it’s something that I’ll think about in future versions, since I think it could alleviate the issue when replicating the data.
UserData:
"Fn::Base64":
!Sub |
#!/bin/bash
cd /tmp
wget -O splunk.rpm 'https://www.splunk.com/bin/splunk/DownloadActivityServlet?architecture=x86_64&platform=linux&version=8.0.5&product=splunk&filename=splunk-8.0.5-a1a6394cc5ae-linux-2.6-x86_64.rpm&wget=true'
yum localinstall splunk.rpm -y
export SPLUNK_HOME=/opt/splunk
masterIPAddress=$(aws --region us-east-1 ec2 describe-instances --filters Name=tag:Name,Values=SplunkMaster --query 'Reservations[].Instances[].PrivateIpAddress' --output text)
$SPLUNK_HOME/bin/splunk start --accept-license --answer-yes --no-prompt --seed-passwd Root@123
$SPLUNK_HOME/bin/splunk edit cluster-config -mode slave -master_uri https://"$masterIPAddress":8089 -replication_port 9887 -secret this_key_is_secret -auth admin:Root@123
$SPLUNK_HOME/bin/splunk restart
Finally, the last snippet is the actual Splunk deployment, there are quite a few things hardcoded, for example the actual Splunk version to download, the default user password and the shared secret. The last two are definitely things I want to fix in the next version, but for the sake of this example, this is good enough. Basically, what we are doing here is downloading and installing Splunk, then connecting it to the master instance as a slave indexer. If everything goes right, you can have as many of these as you want at the click of a button. The other two instance types are very similar, changing some lines on the Splunk deployment only.
With this, the instance configuration is done, but we don’t have any Splunk instances actually running yet, and for that we need a second CloudFormation. This one is a lot smaller and basically uses our instance template and deploys our spot instances. Let’s look at a snippet of the index instance.
SplunkPeers:
Type: "AWS::EC2::SpotFleet"
DependsOn: SplunkMaster
Properties:
SpotFleetRequestConfigData:
AllocationStrategy: lowestPrice
LaunchTemplateConfigs:
-
LaunchTemplateSpecification:
LaunchTemplateName: "SplunkPeer"
Version: 6
TargetCapacity: 2
Since most of the configuration was done on our previous file, this one just tells AWS how many instances we want and which template we are gonna use to deploy it. The best part here, and what makes a lot of it work without any hacks, is the DependsOn option, here we can say that this instance will only be deployed after the SplunkMaster has finished, so we shouldn’t have any issues with other instances trying to connect to it before it started the first time.
This is all for the configuration really, on my limited tests, everything worked really well, and I could have everything running in less than 20 minutes! And if I had a deployment server, with all my configuration files there, it could easily scale and totally automated!
Now, there are a few things to keep in mind, this was not tested in production, and if one of the instances goes down, there may be performance degradation (or loss of data) while another one is created and the data is copied over, which could take some time if there is a lot of it. Also, your master instance should never go offline, so it’s one that I would make sure AWS never deletes if the price goes above my limit.
There were a few ideias that I think this could be useful with more testing, since I don’t think having your entire infrastructure running this way is a safe way to go, but maybe if you have your replication factor on on-demand instances, and use spot instances to give better performance at a lower cost, it could help save a buck (how much would really depend on how big is your infrastructure). Also for testing or a staging environments, this would be fantastic since loss of data or degraded performance would be less of a problem there.
Final Words
This time I went a little outside just Security and wanted something more to do with automation, so this helped me learn a lot about CloudFormation, other AWS services that I rarely use and Splunk distributed infrastructure. I think the idea of using spot instances with Splunk isn’t bad, and with more testing and better scripts this could work really well. I also didn’t do any research if anyone else had already published something similar, since I didn’t want to spoil myself or lose motivation or something. Also, if possible I still want to do more here, improve the script since there are a lot of things to change and also to add a few other services, like a deployment server and universal forwarders.
If you are interested, you can check the full code on my Github repository here
Next post I want to do something more with monitoring, or some automation in the SOAR style, I have a few ideas that I want to pursue, and while I do love Splunk, I also don’t want for this to be a blog that everything uses Splunk. Anyway, I hope I can work something for the next one in a shorter time frame.
Thank you for reading.
~Akai
Dionaea honeypot and Splunk
2020-06-08
Before I begin, the data presented here is a little old already, eveything was done at the end of April, but only now did I got around to write this post.
Recently I started messing around with the Dionaea honeypot, in this post I want to describe my experiences in deploying and configuring both Dionaea and Splunk for monitoring. Dionaea is a low interaction honeypot, this means it emulates a few network protocols, while giving the attacker very little interaction with the system, so it probably won’t be capturing any advanced attacks because of that, but it’s quick to deploy and is low maintenance.
Infrastructure
Everything is running on Amazon Web Services (region us-east-1), the honeypot runs easily on a t3a.nano and it’s the cheapest. The Splunk instance is running on an t2.micro, only because it’s on the free tier, since it’s definitely not enough when doing visualizations with lots of queries and a half decent time frame, I had Splunk crash on me more than once because of this.
The honeypot is running on Ubuntu 16.04, since it’s what was kind of recommended by the official documentation, and the splunk instance is on a run of the mill Amazon Linux 2 AMI.
Dionaea
The deployment is pretty straight forward when following the documentation, deploying from source didn’t take long and I had no problems.
The default configuration file comes with info logging enabled. In the end I decided to disabled it, as I’m trying to use as little disk as possible to keep costs low, and the ingested volume would be greater than my 500MB/daily limit from the Splunk free license, although I didn’t try it after disabling a few services on Dionaea. Talking about services, I opted for disabling the mssql and mysql services, since I was getting blasted with brute-force attempts, and I wasn’t very interested in them either way, while they were up, all I saw was attempts with the user “sa” and password from some premade list (things like “111111”, “222222”, “qwerty1” and so on). The other services I left untouched, at least for now. Also enabled JSON logging, which took me a while to get right, since the default file is missing a ‘/’, finally managed to find the solution on an issue on Github, but not forgetting the file:// protocol would have helped…
One of the issues I had was that the current JSON logging format does not store the MD5 hash of the payloads, I did try messing around with the code but after a few hours I couldn’t make it work, so since the SQLite module does have more information, I created a simple script that connected to the SQLite and pushes an event with hash and some other information, and left it to run every few minutes using CRON looking for new hashes.
Splunk
Here I was a little more at home, but it still had been a few months since the last time I configured anything on Splunk, it took a bit of trial and error, especially when extracting timestamps from the JSON events.
Finally looking at some visualizations, the GIF bellow shows the dashboard with a 3 to 4 day timeframe, as you can see, there is filtering for protocol, source ip and country, also most of it is interactive, meaning that clicking on something will filter the dashboard for that item.
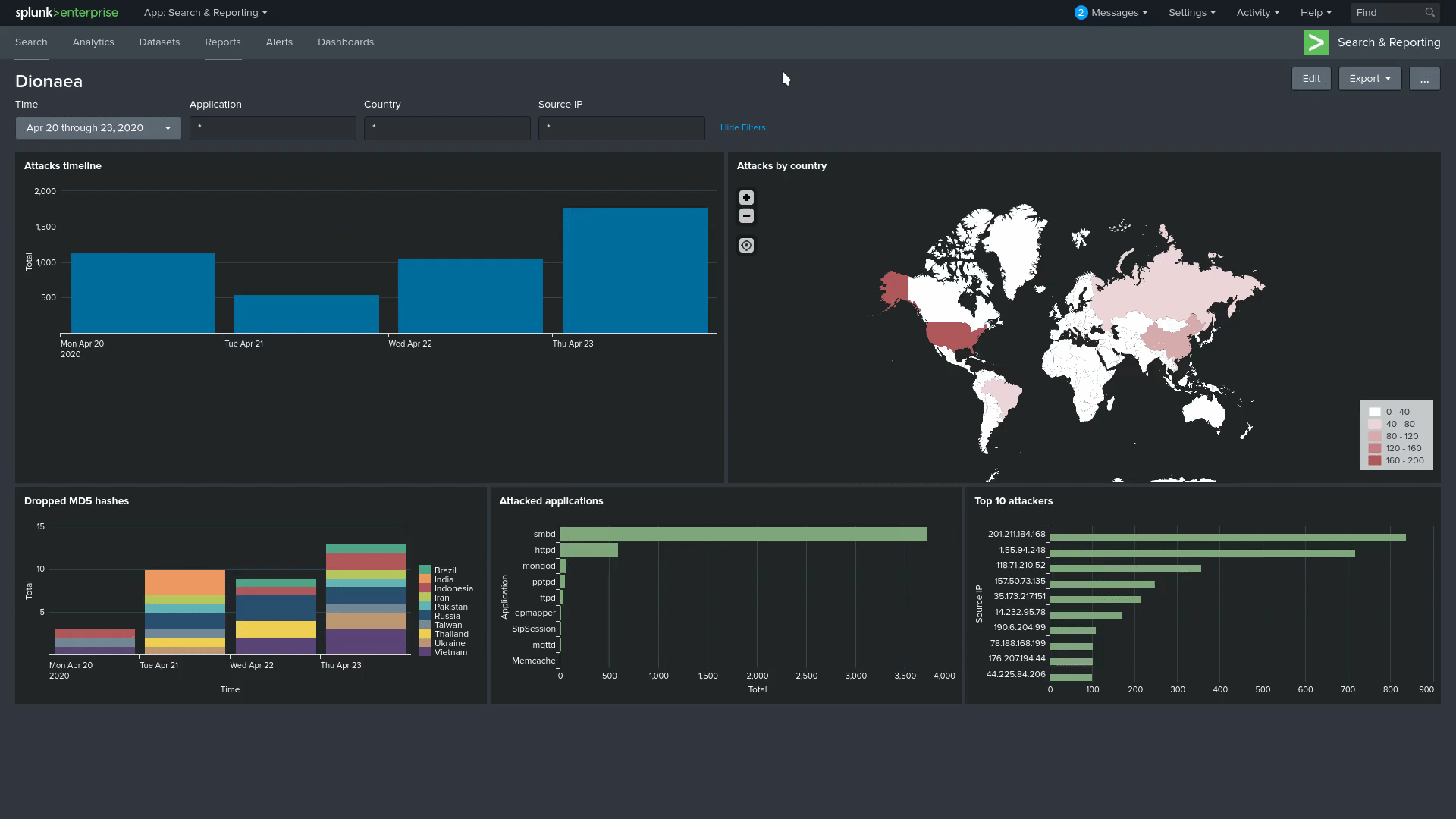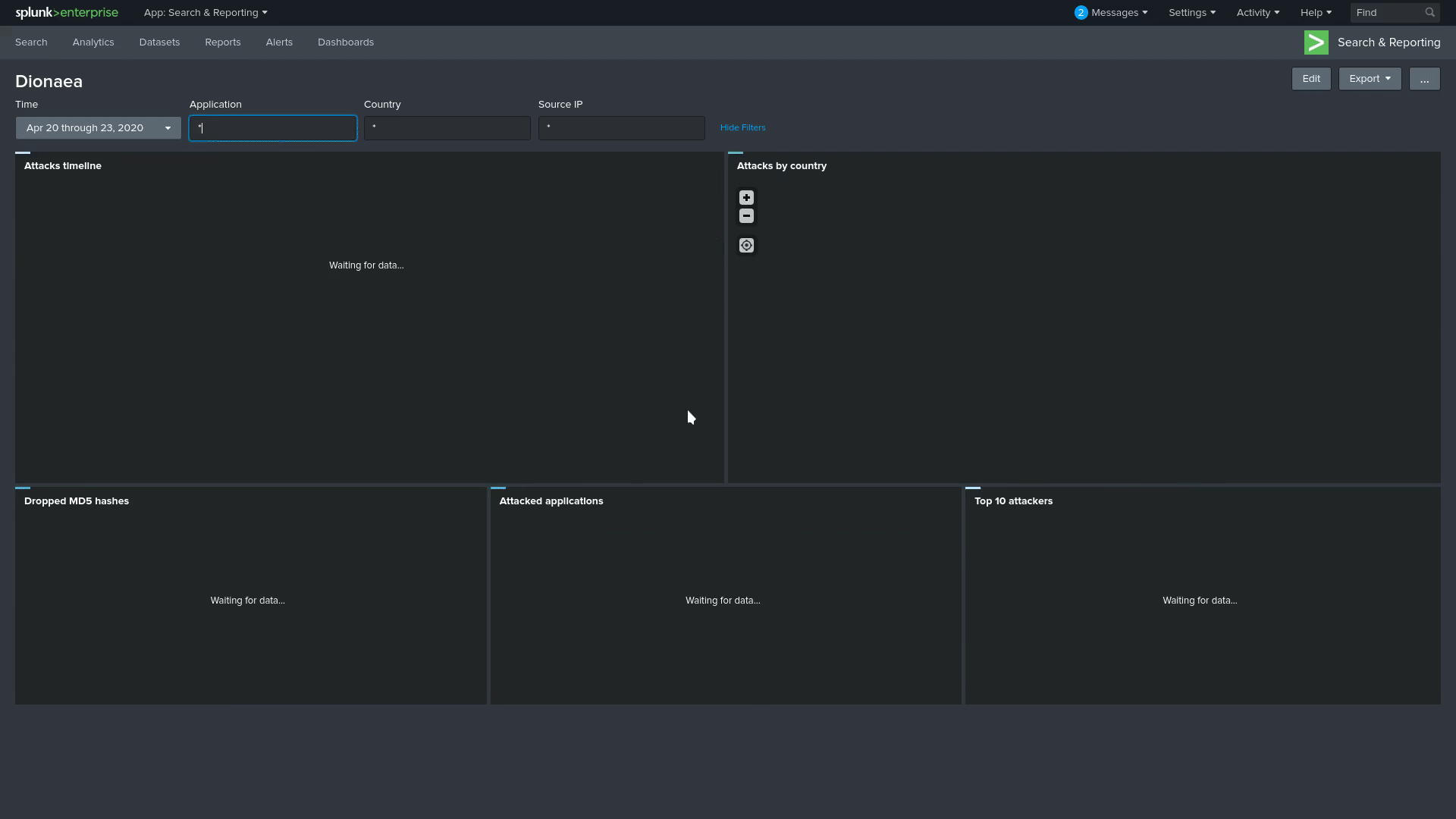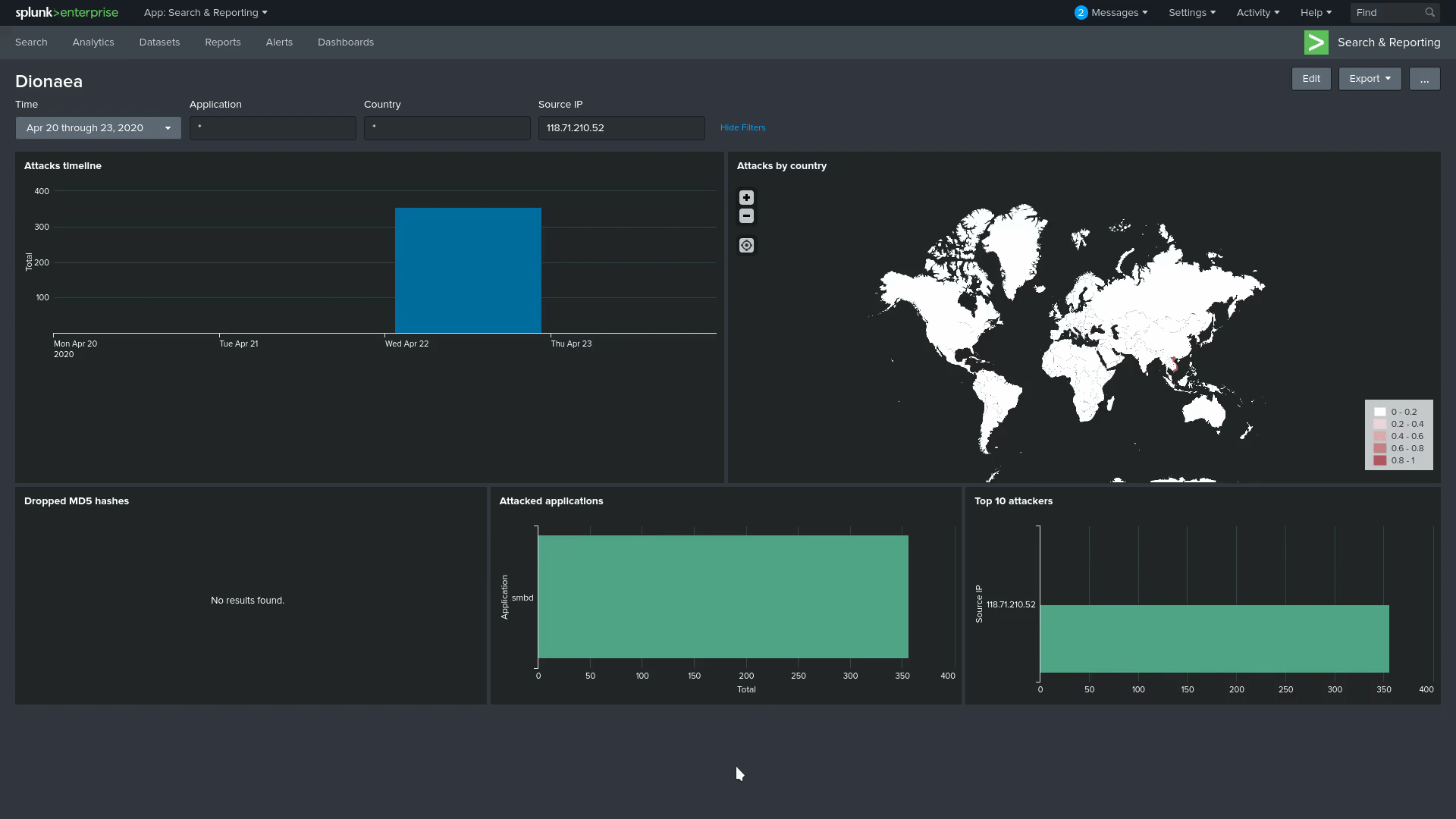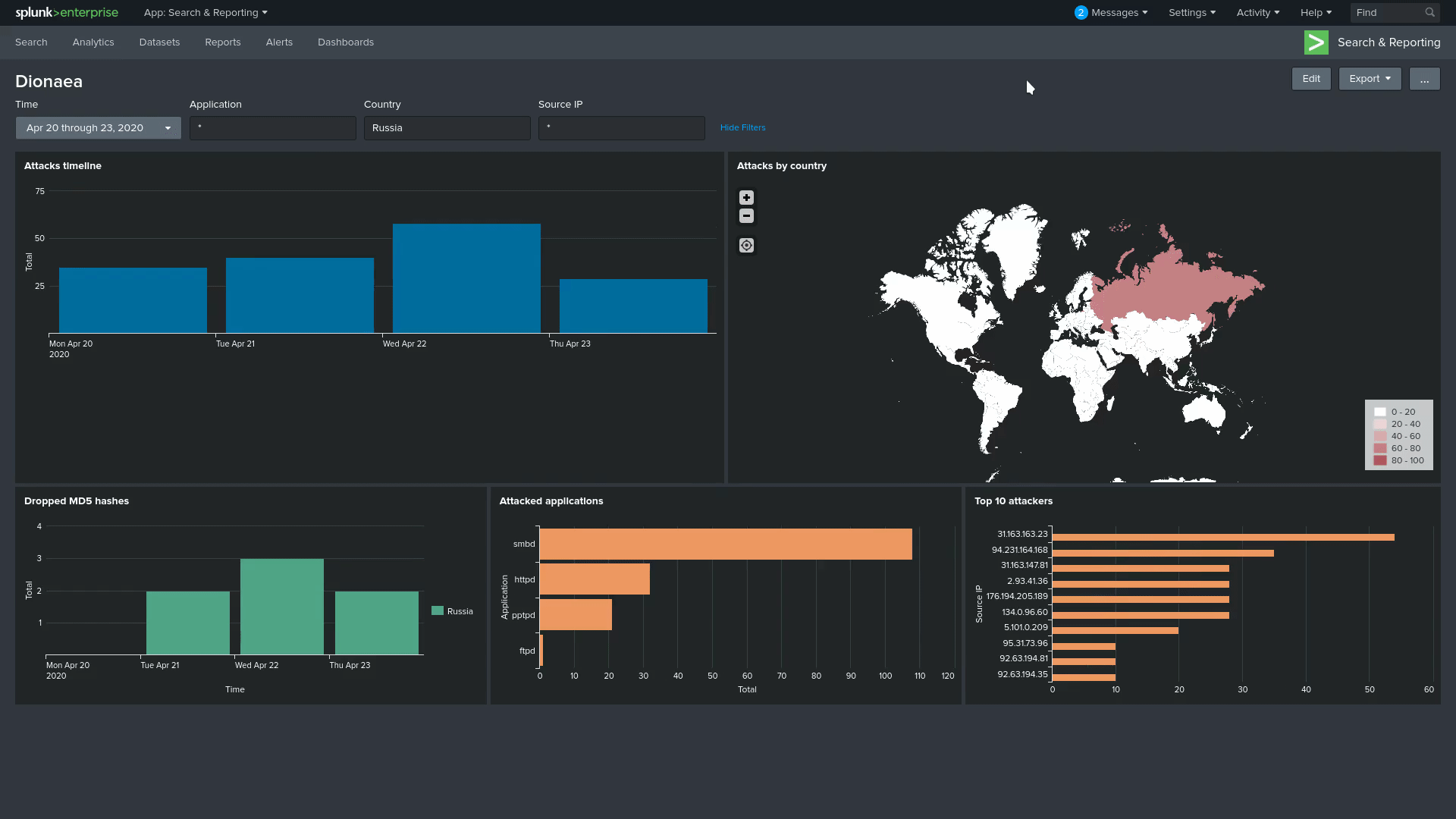
Some explanation for the tiles, from left to right, top to bottom, we have the Attacks timeline, showing how many attacks we got on the timeframe; Attacks by country uses the source ip to pinpoint where the attack came from, the darker the colour the more unique IP attacks we had from that location; onto the second line we have the Dropped MD5 hashes, similar to the previous timeline, except this one shows which country dropped a payload and when; next we have the Attacked applications, a summary of how many attacks each application got during our time frame, it’s easy to see that smbd is by far the most popular; for the last one, we have the Top 10 attackers by IP with the biggest attackers.
Final Words
This is my first real publication, so I’m not really used to writing a blog and how I wanna do things. In the end it was interesting to see that Russia and China weren’t the top attackers, the US got them beaten most of the time. I still wanna see if I can improve on the visualizations, and get the logging working properly, without resulting to a little hack. All the payloads I got were already on VirusTotal, so I’m debating creating or not the integration that Dionaea provides, since VirusTotal doesn’t allow searching with the public API, it would be just another comment about getting the sample with Dionaea, or maybe I can look onto some open threat intelligence tool and integrate with that. Finally, I still want to try some other honeypots, probably the ones with a higher interaction, or even deploying Dionaea on different regions to see if there is a noticeable difference on the attacks.
This was a really interesting project to do, not just because I managed to work a little more on Splunk, but it was also really fun seeing all the traffic you can get from just having a machine open to the internet.
Thank you for reading.
~Akai